二八法则,要学会抓重点
01 幂律分布
帕累托 1896 年观察到 80% 的意大利土地归 20% 的人所有,豌豆产量也类似。Juran 在 1940 年代把它推广为通用原则,叫 "vital few, trivial many"
但二八不是巧合,背后是幂律分布:$P(X > x) ∝ x^{-α}$,城市人口、词频、地震震级、网站流量、财富、代码热点函数耗时——都是幂律的具体投影
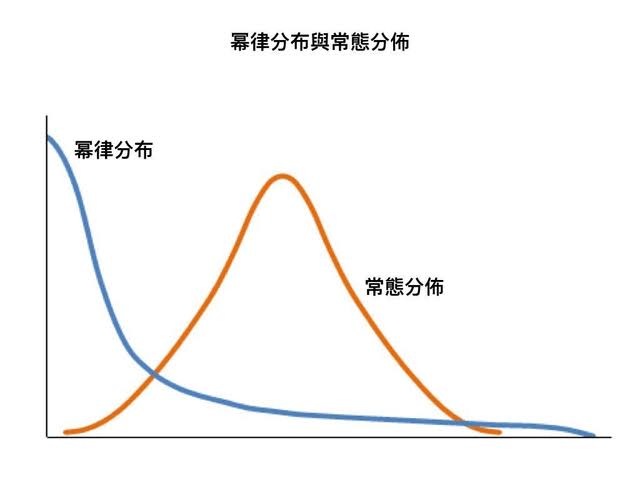
幂律分布跟正态分布是两个世界:
- 正态世界里:平均值有意义,身高体重考分都在均值附近聚集
- 幂律世界里:头部主导一切,平均收入跟中位数能差一个数量级
幂律分布表示重要性是不均衡的,在幂律分布场景中平均用力是最差的策略
02 反二八场景
二八法则不是万能锤,判断它能不能用,问一个问题:
在这件事上,"够用"算不算成功? 如果够用就行,可以二八不要追求完美;如果必须做到极致,要求必须不出事,那就是反二八的场景
适用场景——投入产出近似线性,且边际收益递减,做到"够用"就有大头收益:
- 找营收大客户:20% 客户带来 80% 营收,资源向他们倾斜
- 修产 bug 最多的模块:少数模块产出大部分线上故障,集中改造它收益最大
- 砍掉低 ROI 的会议 / 流程:识别那些占时间但不产价值的部分,直接去掉
- 先学高频 API:一门新语言或框架,20 个核心 API 覆盖 80% 日常使用
反二八场景——边际收益递增,或存在硬阈值,"差一点点"就等于失败:
- 软件项目的最后一公里:前 80% 功能花 20% 时间,剩下 20%(边界条件、性能、稳定性)花 80% 时间
- 运动员训练 / 乐器演奏:前 20% 让你"会",后 80% 让你"行",决定上限的恰恰是后 80%
- 安全 / 可靠性 / 医疗:从 99.9% 到 99.999%,每多一个 9 都需要数量级投入,省不掉
- 基本功(数学、写作、英语):前期投入不会立刻产 80% 收益,但会持续作用于后面所有事,时间维度上反二八
一句话:二八适用于找瓶颈、砍冗余,不适用于突破上限、保下限
03 怎么用:分三层递推
二八法则不能扁平地用,要按三个时间尺度递推:
战略层(3-10 年)——定方向与远景:解决"去哪里"和"成为什么样的人",是长期的全局规划。核心动作是人生定位、选择赛道、建立个人核心护城河。例如,通过构建跨界能力,在未来 5 年内转型为具备商业化能力的复合型业务专家,而非单一技术岗
战役层(6 个月-2 年)——定节点与战果:解决"打哪几场硬仗",是连接战略与战术的桥梁,把宏大目标拆解为可落地的里程碑。核心动作是资源配置、阶段性成果产出、重大项目落地。例如,为达成专家目标,今年内拿下某项行业核心资格认证,并主导完成一个跨部门的标杆项目
战术层(每天-1 个月)——定方法与动作:解决"具体怎么打",是最微观最具体的每日执行,强调工具与效率。核心动作是刻意练习、时间管理、PDCA 循环复盘(计划、执行、检查、调整)。例如,每天早晨用番茄工作法专注学习专业资料 1 小时,每周撰写一篇技术博客输出
大多数人卡在战术层不停发力,根本原因往往是战役层缺位、战略层走偏——天天忙着打怪练级,却没想清楚这是哪场仗、最后要走到哪
04 战略层:选高价值高优势的头部
幂律意味着每个赛道都有头部。一个系统里,头部品牌吸引约 40% 的注意力,第二名 20%,第三名 7%–10%,剩下所有人共分 30%。头部不止收益高,加速度也更快——优势带来名声,名声带来机会和资源,循环放大,最终拉开数量级差距
把"赛场价值"和"个人优势"两个维度交叉,就是头部矩阵:
- 头部(高价值 + 高优势):风口上的独角兽、热门赛道的核心岗位
- 肥尾(高价值 + 低优势):独角兽里打杂的、名校里的差生
- 小山头(低价值 + 高优势):偏门领域的第一名、小公司的核心员工
- 沙漠(低价值 + 低优势):非核心公司的非核心岗位
目标显然是头部。难点不在"知道要去头部",在进头部时本能反应几乎全是错的,避开三个常见误区:
4.1 从价值出发,而非从优势出发
直觉是先盘点"我有什么",再找匹配的赛道。这条路的问题:
- 过去的优势不等于未来的优势:固守舒适区里的优势,恰恰最没有优势
- 场外没法判断真正的优势:核心优势是在战场上一次次逼出来的,不是在地图上定下来的
正确顺序是先看哪里高价值,再思考自己怎么入场。高手选窄门——只要方向正确,资源、技能、优势都可以积累
4.2 不要在热门赛道随大溜
高价值赛道竞争也激烈。当所有人都涌向新大陆,本能反应是"再不上就来不及了"。但激烈竞争里,没有差异化优势就是炮灰——内容创业风口下成功的咪蒙、六神磊磊、连岳,都是先在自己的小赛道深耕多年才正好赶上风口的人,不是临时入场的人
入场前用足够时间观察对手、想清楚差异化。这就是 OODA 循环:observe → orient → decide → act,观察永远在前。巴菲特办公室不放当日股价显示器,是同一个道理——避免被本能裹挟
4.3 从身边的头部做起
"我要成为业内最好的 X"是太空漫步——既没见过"业内",也没见过"最好"。头部是你能触及、能参与的赛道里的高价值高优势区域,不是新闻里那个
- 在小团队里,先成为团队头部
- 是三四线小老板,先击穿当地市场
- 是个快递员,先成为这片区的头部快递员
再小的系统头部都有正反馈。从鸡头变凤头,再从小头部走向大头部,比一开始空降到顶级赛场更稳
05 战役层:把方向拆成可打的硬仗
战略层告诉你"去哪里",但 5 年的方向不能直接执行。战役层的作用是把"成为复合型业务专家"这种远景,拆成 3-5 场有明确战果、能在 1 年内验证胜负的硬仗
战役不是任务清单,它必须满足三个条件:
- 可结项:有清晰的"打赢了"标志(拿到证书、项目上线、晋升、对外文章被引用),而不是"持续学习"这种没有终点的状态
- 可独立验证:不依赖战略层全部成立,单独打赢一场也有价值——这样即便方向需要调整,沉淀下来的能力也不浪费
- 资源够得着:人、时间、预算、关系,都在你能调动的范围内;调不动的不是战役,是幻想
一年最多打 2-3 场。战役多了等于没有,因为每场都需要持续投入和阶段性资源倾斜。挑战役的标准也是二八:哪一两场打赢了,能让战略层完成度跳一大档,就打哪个
战役层最容易出的两个问题:
- 战略-战役不对齐:战略要"复合型",战役却全是单一技术深挖——打赢了也不通向战略
- 战役-战术不对齐:战役要"主导一个跨部门项目",每天的战术却是埋头写代码不参与协调——战术再勤奋,战役还是输
每个季度问自己一次:**这场战役还在不在牌桌上?**赢了就结项、换下一场;输了或战场消失了就果断放弃,别把战术惯性当战役进展
06 战术层:进入战场后识别那 20%
选好战场,下一步是在场内抓 20%。新手常见错误是"系统学习",从教材第一章读到最后一章,这是最低效的路径——因为事先并不知道哪 20% 重要
6.1 找映射
跨领域学习时,那 20% 不是别人画的"知识地图重点",而是在旧领域已掌握知识在新领域的投影
建立已经掌握的知识体系和新领域知识的映射,对比学习,事半功倍
比如,在学习 Spark 内核时,别直接从 SparkSession.sql() 入口往下读——那是新人的路径,对带着旧领域直觉的人是浪费。从认识的算子横向切入:直接打开 SortMergeJoinExec,对照脑子里的 PG 实现,看它怎么接到 codegen 里,这种对比学习不会迷路
6.2 识别枢纽概念
新领域里高频出现、且解释别的概念时反复被引用的,几乎一定是 20%
操作上:刚开始不要急着学,先做高频词统计。翻最近 50 个 PR 的 title、最近一个月的 issue、团队内部设计文档,看哪些词反复出现。例如,Spark 里的 TreeNode、Stage、Exchange、AQE、DAGScheduler、Shuffle 一定会冒出来——它们就是那 20%
6.3 从输出反推输入
正确做法是找团队最近的一个具体产出(PR、perf 优化、bug fix),把它读懂。读懂它所需的全部前置知识,就是你接下来一两周的 20%。带着具体问题学不会迷路;学完直接能用,复习成本为零
6.4 二八的二八,把法则递归起来
二八法则不是一次性应用,要在两个维度递归:
空间维度(向内)——那 20% 里依然遵循二八法则:
- 二八法则:20% → 80%
- 二八二次方:4% → 64%
- 二八三次方:0.8% → 51.2%
同样总投入下,平均用力者的单位产出是 1(100% 投入产 100% 产出),递归三层后单位产出是 64(0.8% 投入产 51.2%)——效率差 64 倍。最难也最值钱的是持续找到那核心的 0.8%,天使投资人在 B 轮以 100 倍收益退出,付的就是当年识别这核心 20% 的钱
时间维度(向前)——20% 是一直在变的,每周问自己一次:"如果下周就要出活,我现在最该搞懂的一件事是什么?" 第一个月是 Catalyst TreeNode + Scala 模式匹配;第二个月是 Shuffle 与 Tungsten;半年后大概率是 AQE;两年后可能是某条具体的优化器规则
两个维度都失败的常见后果:
- 学不会"找映射",会迷失在新领域的术语丛林里
- 学不会"滚动",会卡在早期阶段反复学那个 20%
- 不会向内递归,停在 80 分,吃不到那 64x 的复利
07 结语
二八法则不教你"怎么努力",它只教你"在哪里偷懒";要做的不是少学,是更准地学